
Your Copilot to
Fully Governed
AI Pipelines in Minutes,
at 1/5th the Cost
Meet FeatureByte, a first-of-its-kind AI data platform
Try FeatureByte for Free
or request an


A Copilot for the
entire feature lifecycle
Feature creation to production serving - in minutes
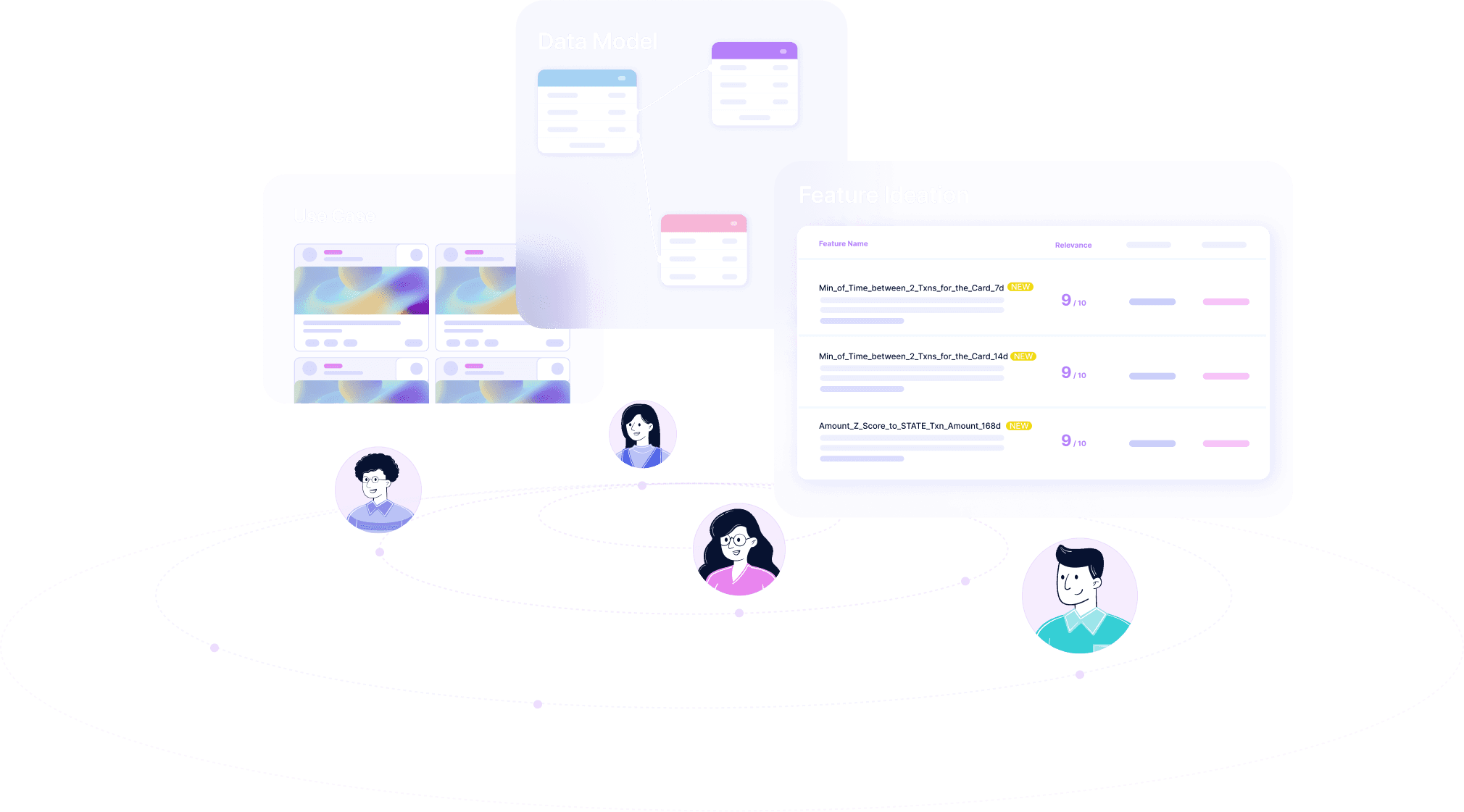
Let FeatureByte Copilot ideate features for your use case automatically, or create them with just a few lines of code. Experiment immediately and serve features instantly. Leave the plumbing and pipelining to FeatureByte.

Boost model accuracy through data
It’s no secret that great feature engineering does wonders for model performance. Generate state-of-the-art features automatically using FeatureByte Copilot, use those built by your team, bring your own transformers or transform creative ideas into training data in minutes.

Do more with less
Deploy more models in production, faster, using 1/5th of the compute and resources required for legacy approaches. Empower data scientists and ML engineers with a self-service platform, reducing dependence on other teams.

Unlock AI at scale in your enterprise
Collaborate seamlessly. Manage feature sprawl with a self-organizing catalog. Monitor pipeline health and costs centrally. Stay in control with enterprise-grade role-based access and governance workflows.

Try FeatureByte Copilot
FeatureByte Copilot dramatically accelerates your AI journey by automatically ideating features for your data model and use case. Spend less time manually creating features and more time solving value-add problems.
