Feature Engineering, Aggregation, and Speed
Recent Posts
In a recent blog, I highlighted the importance of aggregation in aligning features with the unit of analysis and the use case. However, after testing pandas in-memory aggregation on a small dataset, I discovered that pandas requires excessive RAM resources and this algorithm is not scalable.
To address this issue, I tested an alternative approach to pandas aggregation. This algorithm involves aggregating one entity at a time and then concatenating the results. One advantage of this method is that RAM usage remains constant regardless of the entity count, although it does increase with the event count.
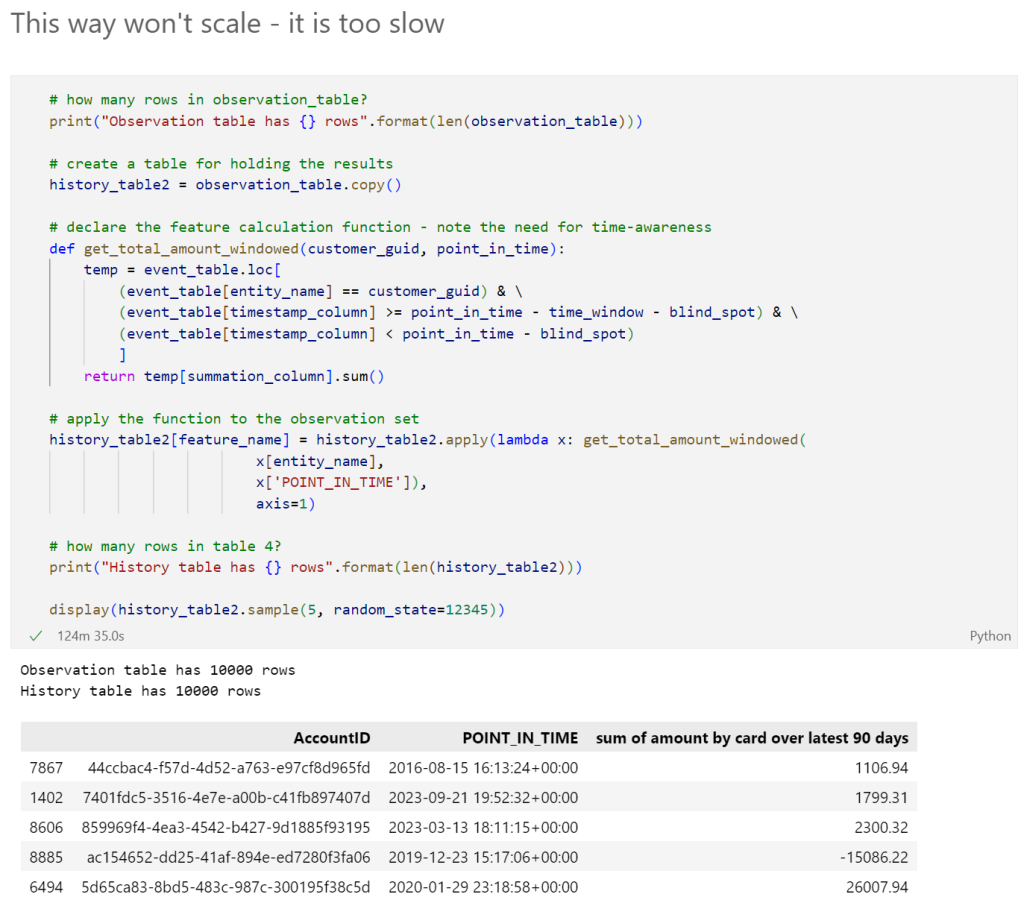
However, it should be noted that the one-entity-at-a-time algorithm is considerably slower, taking more than 2 hours to aggregate 10,000 customers, compared to the mere 10 seconds required for the in-memory approach. This algorithm is more than 700 times slower! While this alternative algorithm is more scalable in terms of RAM usage, it does not scale well for elapsed time, especially for large entity counts. For instance, a business with 100,000 customers would need an entire day to complete the feature engineering calculation of just one feature!
With in-memory pandas aggregation not scalable in RAM usage and the one-entity-at-a-time algorithm not scalable in processing time, our only choice is to explore other options. One possibility is to push the aggregation task to the database. While this approach can be effective, it often necessitates writing complex and convoluted SQL queries, commonly referred to as “spaghetti SQL.” Another option worth considering is caching the aggregated values. This involves storing pre-calculated aggregated results, but it can result in significant storage space consumption within the database.
Not all feature platforms address these challenges. Look for a feature platform that offers similar simplicity and abstraction to pandas, enabling ease of use and straightforward operations. Additionally, the ideal platform should leverage the power of a database by automatically generating optimized SQL queries to offload processing into a database cluster. Furthermore, a feature platform should intelligently cache feature values to optimize both processing speed and storage efficiency, striking a balance between performance and resource consumption.
Looking for a feature platform with pandas-like syntax, in-database computing, and optimized caching? Download the free FeatureByte SDK and test it out on your enterprise data https://docs.featurebyte.com/latest/
Explore more posts

