MLOps: AI Data Latency
Recent Posts
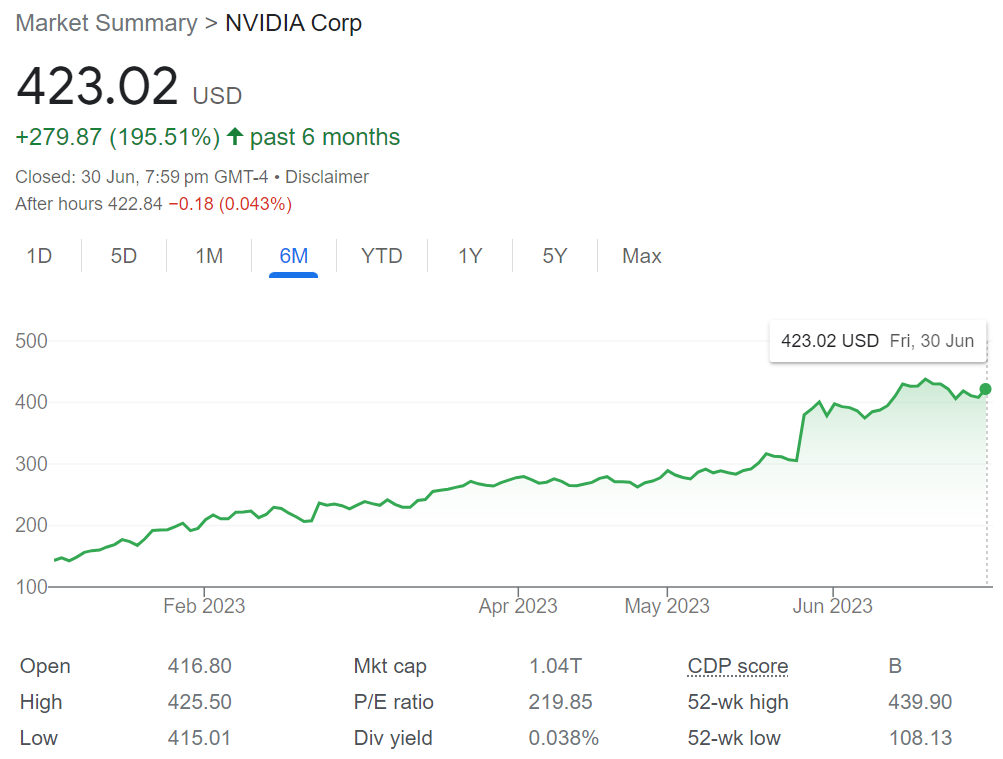
Nvidia’s stock price has experienced a remarkable increase of nearly 200% in the first half of 2023. Their success can be attributed to the pivotal role that GPUs play in powering machine learning algorithms. Nvidia GPUs are in high demand due to the growing importance of running increasingly complex AI systems at scale with low latency. However, all these efforts could be in vain if we fail to address a significant bottleneck in the production AI pipeline – the latency challenges associated with AI data.
In the modern data stack, AI data is typically sourced from data warehouses that prioritize analytics rather than live transactional databases. Consequently, AI data may not always be up-to-date or fresh. This poses a challenge for AI systems, which must be designed to account for blind spots caused by the lack of data freshness. Machine learning algorithms often require computationally complex data processing, such as cross-aggregation, embeddings, and entropy calculations. Additionally, event data needs to be aggregated before it can be utilized by machine learning algorithms, and time-aware windowed aggregations and table joins for feature engineering are computationally intensive and time-consuming.
To mitigate these challenges, the concept of a Feature Store has emerged. The primary purpose of a Feature Store is to centralize pre-calculated feature values, significantly reducing the latency associated with feature serving during both the training and inference stages of AI systems.
However, many feature stores adopt a “log and wait” architecture, meaning they only calculate feature values from the time the feature calculation is first declared. This approach is not compatible with the agility and experimentation required by data scientists. Additionally, feature stores solely store the calculated values and do not manage or determine how features are calculated. Consequently, feature stores do not handle feature versioning, requiring users to manually create new feature names when changes are made to feature calculations. Failing to account for blind spots when declaring features can lead to AI systems expecting data that is not yet available, resulting in underperformance.
Feature stores offer a solution by pre-computing feature values as data becomes available, thereby reducing latency. However, it is important to ensure that the chosen feature store supports automated time-aware backfilling of feature values. Feature stores are valuable starting points, but a feature platform may be required to achieve desired results. As well as managing feature declarations, feature platforms offer essential capabilities such as addressing data freshness blind spots, abstracting the complexity of feature declarations, automatically generating SQL/Spark code for populating the feature store, as well as governance, approval, and version control processes. Learn more about feature platforms here.
Explore more posts

